Công nghệ xác định kiểu gen và kiểu hình trong nghiên cứu Gen dược học

Trungtamthuoc.com - Trước khi có thể tiếp cận với nghiên cứu và ứng dụng của gen dược học trong thực tiễn, một điều kiện rất quan trọng là phải hiểu được các hướng tiếp cận, các phương pháp đánh giá và nghiên cứu, từ đó, lựa chọn được những cách tiếp cận phù hợp với mục tiêu và điều kiện cụ thể.
1 Ý nghĩa SNP, Haplotype trong nghiên cứu Gen dược học
Trong các kiểu đa hình gen, đa hình đơn nucleotid (SNP) phổ biến nhất, do vậy có thể coi SNP là đối tượng nghiên cứu chính của Gen được học. Tuy nhiên, các nhà khoa học đã khám phá ra hệ gen người có chứa khoảng 10 triệu SNP. Chính vì vậy, sẽ rất khó khăn, tốn thời gian và tốn kém để xem xét từng thay đổi này và xác định liệu nó có đóng vai trò trong bệnh và đáp ứng với thuốc của con người hay không. Do vậy, việc nhận dạng bản đồ SNP của mỗi người là một việc làm tưởng chừng như không thể với thế giới khoảng 10 tỷ người. Tuy nhiên, rất thú vị là có một sự kết hợp của một số SNP lân cận, liên kết chặt chẽ với nhau và được di truyền liên kết cùng nhau từ thế hệ này sang thế hệ khác trong những khối lớn (trên cùng một nhiễm sắc thể), gọi là các khối Haplotype hay "Haplotype block". Sự đồng di truyền của các SNP trên các Haplotype này dẫn đến sự liên kết giữa các alen này trong quần thể (được gọi là mất cân bằng liên kết - linkage disequilibrium (LD)). Những khối Haplotype như vậy tương đối phổ biến, có xu hướng theo khu vực dân cư và chủng tộc. Do đó, một Haplotype cũng có thể được sử dụng làm chỉ dấu (marker) trong nghiên cứu Gen được hoặc bất kỳ một SNP trong nhóm cũng có thể được sử dụng làm chỉ dẩu (marker) cho toàn bộ khối. Kết quả là, chỉ cần một vài trong số các “SNP gắn thẻ” (tag SNP) này để xác định từng Haplotype phổ biến trong một vùng của nhiễm sắc thể (Hình 4.1). Sự kết hợp của các SNP thành Haplotype giúp giảm số lượng SNP cần phải sảng lọc (một SNP cho biết thông tin về cả một nhóm gen liên kết), do đó nghiên cứu về Gen được học đơn giản hơn, nhanh hơn và hiệu quả hơn nhiều. Ngoài ra, cấu trúc Haplotype chứa nhiều SNP có thể cung cấp thông tin chính xác hơn về mối quan hệ kiểu gen - kiểu hình so với SNP đơn lẻ.
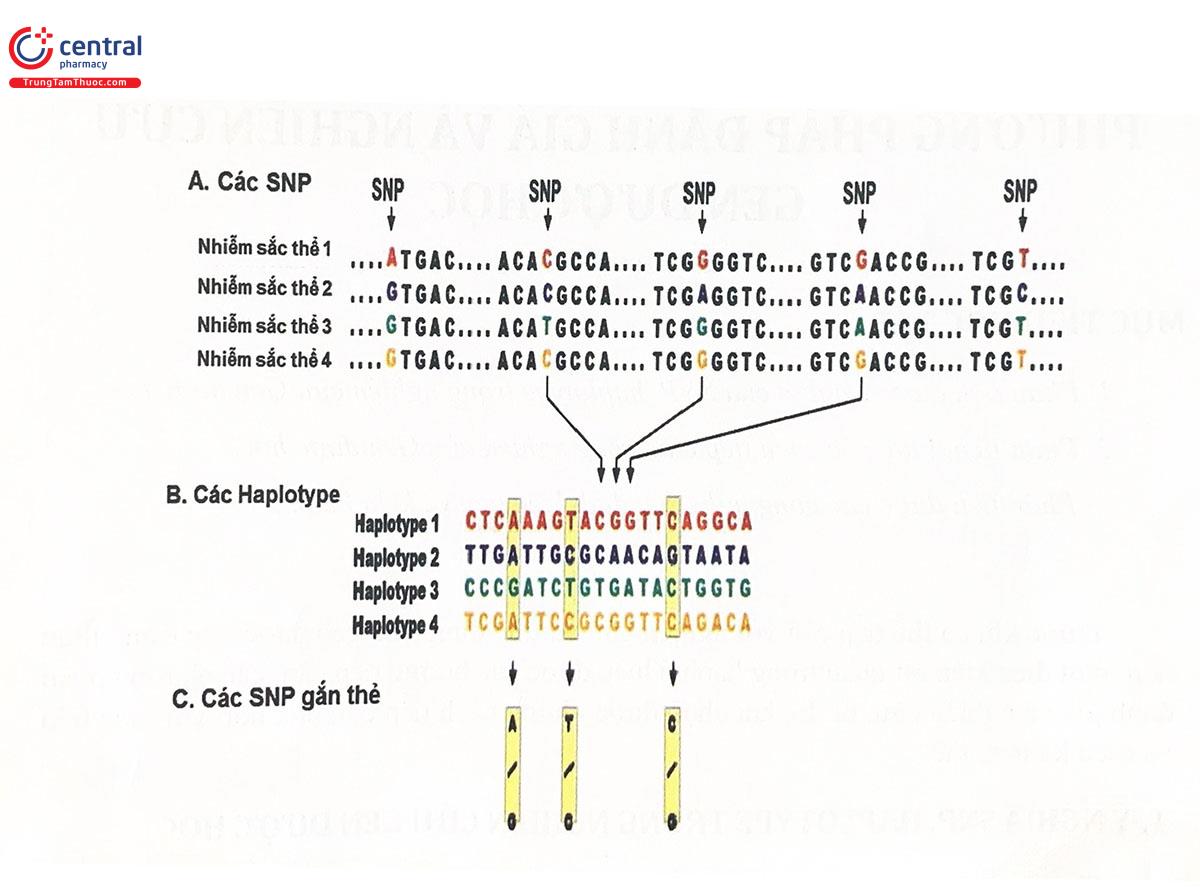
A. Các SNP: Một đoạn ADN từ bốn phiên bản của cùng một vùng 6 kb ở những người khác nhau, trong đó hầu hết trình tự các chuỗi là giống hệt nhau trở 5 vị trí nucleotid bị biến đổi. B. Các Haplotype: 4 Haplotype này là sự kết hợp đặc biệt của các alen ở 20 SNP gần nhau trong vùng 6 kb. C. Các SNP gắn thẻ: Chỉ cần xác định kiểu gen của 3 SNP gắn thẻ trong số 20 SNP trên là đủ để xác định bốn haplotype này
Một SNP gắn thẻ có thể cung cấp thông tin về một SNP khác hoặc về hàng trăm hoặc hàng ngàn SNP trong chuỗi ADN kéo dài hàng ngàn kilobase. Thông tin này đặc biệt có liên quan trong việc thiết kế các nghiên cứu liên kết trên toàn hệ gen (GWAS). Tần suất xuất hiện của các alen SNP, Haplotype và các tag SNP cụ thể khác nhau giữa các nhóm dân tộc và điều này đã được phân loại thông qua Dự án HapMap (www.hapmap.org).
Dự án HapMap là một dự án có tính hợp tác quốc tế với quy mô rất rộng. Mục đích của dự án là lập được bản đồ Haplotype bao gồm vị trí của chúng trong hệ gen và mức độ phổ biến của chúng trong các quần thể khác nhau trên toàn thế giới liên quan đến tính đa hình gen người thông qua việc tìm hàng triệu SNP từ những người tình nguyện trên khắp thế giới. Vì số lượng SNP có thể lên tới vài triệu, nên nhiệm vụ chính của Dự án HapMap là sắp xếp chúng sao cho các phân tích được dễ dàng hơn. Dự án này quy tụ rất nhiều các nhà khoa học từ các quốc gia như Anh, Mỹ, Canada, Nhật Bản, Nigeria và Trung Quốc... và đã lập ra bản đồ Haplotype của người bằng cách dùng các mẫu ADN của các nhóm sắc tộc khác nhau trên thế giới. Cho đến nay, dự án đã tìm ra khoảng hàng triệu SNP và tập trung vào các SNP xảy ra thường xuyên trên cả hệ gen. Sử dụng Dự án HapMap sẽ giúp chỉ ra được nguyên nhân gây ra các căn bệnh di truyền và từ đó phát triển các phương pháp điều trị hiệu quả hơn, tiến tới sẽ áp dụng với việc cá thể hóa trong sử dụng thuốc. Việc lập bản đồ SNP và tần suất xuất hiện của chúng trong các quần thể khác nhau có thể giúp tăng tác dụng của thuốc theo từng dạng đa hình gen thể hiện khác biệt trong các chủng tộc và rất có ích trong việc tăng hiệu quả nghiên cứu di truyền. Dự án cũng sẽ giúp con người hiểu các tiến trình quan trọng khác trong sinh học, chẳng hạn như tiến hóa, tái tổ hợp và những tác động tạo nên các biến thể gen người.
2 Các cách tiếp cận trong nghiên cứu Gen dược
Các nghiên cứu về Gen được học liên quan đến việc phân loại hoặc xác định các chất chỉ dấu (marker) được sử dụng để dự đoán sự khác biệt giữa các bệnh nhân liên quan đến hiệu quả và an toàn thuốc. Có hai cách tiếp cận chính trong nghiên cứu gen dược: Phương pháp tiếp cận gen ứng viên (candidate gene approach) và cách tiếp cận trên toàn bộ hệ gen (genome wide approach).
Trong cách tiếp cận gen ứng viên, nghiên cứu chỉ quan tâm đến một số lượng nhất định các biến thể của một gen hoặc một vài gen được biết có liên quan đến được động học và/ hoặc dược lực học của thuốc. Do đó, loại nghiên cứu này còn được gọi là các nghiên cứu về mối liên quan dựa trên giả thuyết. Đây là một cách tiếp cận hợp lý và được áp dụng phổ biến trong các nghiên cứu gen được. Ví dụ như nghiên cứu về gen TPMT (mã hóa cho thiopurine S-methyltransferase, enzym chuyển hóa 6-mercaptopurin). Kết quả của nhiều nghiên cứu cho thấy, có mối liên quan chặt chẽ giữa kiểu gen TMPT và kiểu hình hoạt tính của enzym tương ứng. Khoảng 80 - 95% bệnh nhân có hoạt tính TPMT thấp có thể được giải thích bằng sự xuất hiện các alen TPMT*2, *3a và *3c trong kiểu gen. Kiểu gen đồng hợp tử hoặc dị hợp tử của các alen này tương ứng với kiểu hình giảm hoặc mất hẳn hoạt tính chuyển hóa của enzym TPMT. Do vậy, việc giảm liều 6-mercaptopurin đến 50% được khuyến cáo ở người mang kiểu gen biến thể TPMT dị hợp tử và đến 90% được khuyến cáo ở người mang kiểu gen biến thể đồng hợp tử.
Tuy nhiên, trong nhiều trường hợp, một gen đơn lẻ không đủ để giải thích sự khác biệt quá lớn về đáp ứng điều trị giữa các cả thể người bệnh bởi con đường dược động học và được lực học của thuốc rất phức tạp, với sự có mặt của nhiều protein khác nhau. Đặc biệt, đáp ứng điều trị với thuốc ung thư là một ví dụ điển hình về sự liên quan của nhiều đa hình gen khác nhau. Ví dụ: Cyclophosphamid được chuyển hóa bởi nhiều enzym CYP khác nhau như CYP2A6, CYP2B6, CYP2C8, CYP2C9, CYP2C19, CYP3A4. Do vậy, sự thiếu hụt di truyền của CYP246 không ảnh hưởng đáng kể tới đáp ứng điều trị với cyclophosphamid. Bên cạnh các enzym chuyển hóa, đáp ứng thuốc còn chịu ảnh hưởng của nhiều protein khác như các receptor, các con đường tín hiệu... Trong trường hợp của các thuốc ung thư, những protein đặc trưng của khối u cũng ảnh hưởng đáng kể. Do tính chất phức tạp như vậy, ảnh hưởng của một gen thường không đủ để dự đoán đáp ứng điều trị của một thuốc. Thậm chí, đó là chưa kể ảnh hưởng của các yếu tố phi di truyền như các đặc điểm lâm sàng của người bệnh, các thuốc dùng kèm. Vì vậy, cần có những nghiên cứu lâm sàng được thiết kế tốt nhằm xác định được mức độ ảnh hưởng của các đa hình gen. Cỡ mẫu của các nghiên cứu này cần đủ lớn (khoảng vải trăm tới vài nghìn bệnh nhân) để đánh giá được mối liên hệ có ý nghĩa thống kê. Ngoài ra, kết quả còn phụ thuộc vào việc lựa chọn gen ứng viên cho nghiên cứu cũng như các biến số làm sảng phủ hợp. Nếu không đủ bằng chứng ghi nhận về mối liên quan với gen ứng viên, việc phối hợp thêm một hoặc một số gen khác có thể làm gia tăng khả năng dự đoán đáp ứng điều trị.
Trái lại, trong cách tiếp cận trên toàn hệ gen, còn gọi là nghiên cứu GWAS (genome wide association studies), nghiên cứu phân tích hàng loạt SNP khác nhau của rất nhiều gen hoặc của toàn bộ hệ gen, không phụ thuộc vào việc các gen này đã từng được biết về mối liên quan tới được động học hoặc được lực học của thuốc hay không. Cách tiếp cận này đòi hỏi phải có các công nghệ phân tích kiểu gen hiệu năng cao, cho phép phân tích đồng thời hàng trăm cho đến hàng trăm nghìn SNP. Đây thường là những SNP phổ biến trong cộng đồng, với tỷ lệ 5 - 10% và thường xuất hiện trên toàn hệ gen. Việc phân tích hàng loạt SNP trên cả hệ gen đòi hỏi các công nghệ tin sinh học tiên tiến để có thể phân tích bộ dữ liệu khổng lồ. Việc thực hiện phép so sánh đa biển cũng cần có phương pháp hiệu chỉnh phù hợp cho nhiều xét nghiệm đồng thời bởi khi có hàng trăm hoặc hàng nghìn phép so sánh đồng thời, rất khó có thể đạt đến giá trị p có ý nghĩa thống kê. Đó là lý do nhiều nghiên cứu GWAS không cho kết quả có tính chất lặp lại.
Tuy nhiên, nghiên cứu GWAS không phải bao giờ cũng quét trên toàn hệ gen. Gần đây, có một cách tiếp cận trung gian mới được áp dụng trong nghiên cứu gen dược, đó là sử dụng các bộ kit cho phép phân tích đồng thời nhiều gen liên quan đến dược động học dược lực học của thuốc. Một số bộ kit có thể phân tích đến 2000 SNP của 225 gen chức năng. Việc giới hạn số lượng gen giúp giảm số lượng các phép hiệu chỉnh cần thiết, do đó, làm giảm nguy cơ sai số. Phương pháp phổ biến trong loại nghiên cứu này là thiết kế kiểu bệnh chứng, trong đó nhóm bệnh là những bệnh nhân đáp ứng tốt sau điều trị với một thuốc nhất định, nhóm chứng là những bệnh nhân dùng thuốc đỏ không có đáp ứng tốt hoặc đơn giản là người khỏe mạnh trong cộng đồng. Cỡ mẫu của loại nghiên cứu này có thể là vài chục cho đến vài trăm bệnh nhân. SNP có khả năng phân biệt tốt nhất hai nhóm sẽ có thể là yếu tố ảnh hưởng đến đáp ứng điều trị của thuốc mục tiêu. Tuy nhiên, kết quả này cần được kiểm chứng trong các quần thể độc lập khác.
Sự khác biệt chủ yếu giữa cách tiếp cận GWAS với cách tiếp cận gen ứng viên là không có giả thuyết định hướng, không cần các hiểu biết về PK/PD của thuốc. Do đó, nghiên cứu GWAS có thể xác định được những gen chưa từng được biết đến trong lâm sàng. Mặt khác, nghiên cứu GWAS cỏ một số nhược điểm như: Chi phi rất lớn, có thể có yếu tố nhiễu khi lựa chọn nhóm bệnh và nhóm chứng. Ngoài ra, việc phân tích đồng thời hàng loạt SNP có thể dẫn đến âm tính giả hoặc dương tinh giả. Một nhược điểm nữa là nghiên cứu GWAS thường bỏ qua các biến thể gen hiểm do không được đưa vào các bộ kit thương mại, do đó, giảm độ nhạy của nghiên cứu. Một giải pháp cho vấn đề này là giải trình tự vùng gen mục tiêu nhằm phát hiện các biến thể liên quan.
Trong những năm gần đây, số lượng nghiên cứu GWAS tăng lên khá nhanh, với quy mô ngày càng lớn. Ví dụ như một nghiên cứu về liên quan giữa đa hình gen với bệnh bạch cẩu nguyên bảo tủy cấp đã quét đồng thời 400.000 SNP khác nhau. Sự gia tăng này là do có sự phát triển rất nhanh của các công nghệ xác định kiểu gen hiện đại và công nghệ Dữ liệu lớn (Big data).
Với những phát hiện về vai trò của đa hình gen trong sự biến thiên đáp ứng thuốc giữa các cá thể, việc xét nghiệm kiểu gen (genotyping) và xét nghiệm kiểu hình (phenotyping) có ý nghĩa quan trọng, cho phép:
- Đánh giá ảnh hưởng của đa hình gen đối với đáp ứng điều trị
- Phát hiện các đa hình gen liên quan đến đáp ứng với thuốc.
- Dự đoán đáp ứng của từng cá thể người bệnh đối với một thuốc nhất định, từ đó lựa chọn đúng thuốc, đúng liều, đúng liệu trình điều trị.
Tùy từng mục đích, xét nghiệm kiểu gen và xét nghiệm kiểu hình có thể được tiến hành đồng thời hoặc riêng lẻ.
3 Các công nghệ xác định kiểu gen
Công nghệ xác định kiểu gen (genotyping technology) là một trong những yếu tố quan trọng quyết định thành công của nghiên cứu. Không có một công nghệ nào là tối ưu cho mọi nghiên cứu, tùy vào đặc điểm của phòng xét nghiệm, cỡ mẫu, số biển thể cần phân tích và chi phí mà cần lựa chọn công nghệ phủ hợp. Một số hệ thống cho phép sàng lọc không chỉ các SNP mà cả các loại đột biến khác nhau.
Khi lựa chọn công nghệ xác định kiểu gen cần lưu ý các điểm sau:
- Phương pháp được chọn phải xác định chính xác kiểu gen, lý tưởng là thành công ngay trong một lần thử. Một số mẫu có thể thất bại trong lần thử nghiệm xác định kiểu gen đầu tiên; tuy nhiên, phương pháp xác định lại phải nhanh chóng và không tốn kém.
- Phương pháp xác định kiểu gen phải cho phép xét nghiệm nhanh và dễ kiểm định. Trong đó, với sự đa dạng dữ liệu đa hình gen sẵn có, khả năng chia sẽ trong cộng đồng và khả năng chuẩn bị các xét nghiệm một cách kịp thời rất quan trọng xét về hiệu quả và khả năng khám phá trong tương lai.
- Kết quả phải dễ dàng diễn giải, cần sử dụng phối hợp các phần mềm chuyên nghiệp để cung cấp kết quả xác định kiểu gen chính xác, tránh sai số.
- Hệ thống phải có tỷ số hiệu quả chi phí cao, giảm thiểu số lượng hoặc độ dài của các bước trong quy trình xác định kiểu gen. Ngoài ra, các phương pháp cho phép đánh giá nhiều đa hình trong một xét nghiệm có thể giúp giảm chi phí và tăng hiệu quả.
Dưới đây là một số loại công nghệ xác định kiểu gen đang được áp dụng phổ biến trong cả nghiên cứu và trong labo lâm sàng.
3.1 Công nghệ xác định kiểu gen hiệu năng thấp
Loại công nghệ này phù hợp khi số lượng mẫu và số lượng biến thể đa hình cần phân tích nhỏ vì hiệu quả về kinh tế. Các kỹ thuật thuộc loại này chủ yếu dựa trên phản ứng PCR.
Xác định đa hình các đoạn giới hạn của sản phẩm PCR (PCR-RFLP)
Đây là một trong những công nghệ genotyping đơn giản nhất, dựa trên sự có mặt hay không của trình tự nhận biết của enzym giới hạn. Vùng chứa SNP mục tiêu được khuếch đại bằng PCR. Sản phẩm PCR được ủ với enzym giới hạn, phản ứng cắt đặc hiệu có xảy ra hay không tùy từng alen. Sản phẩm cắt có thể dễ dàng quan sát trên điện di agarose, Phương pháp này không cần thiết bị đặc biệt và không đòi hỏi người làm phải được huấn luyện đặc biệt. Tuy nhiên, đây không phải là công nghệ lý tưởng cho mọi nghiên cứu bởi không phải mọi alen được phân tích đều nằm ở vị trí cắt giới hạn của một enzym nào đó.
PCR đặc hiệu alen (alen specific PCR)
Kỹ thuật này đòi hỏi phải thiết kế được cặp mồi PCR bao gồm 1 mỗi chung cho tất cả các alen của gen và 1 mỗi đặc hiệu có đầu tận cùng là base đặc hiệu với alen mục tiêu. Kết quả PCR sẽ dương tính khi trong mẫu có xuất hiện alen mục tiêu. Nếu kiểu gen là dị hợp tử thì sẽ có sản phẩm PCR đối với cả hai loại mối. Kỹ thuật này không đòi hỏi phải có một trình tự cắt giới hạn chứa vị trí SNP nhưng việc thiết kế được mồi đặc hiệu không phải lúc nào cũng dễ dàng và khả thi. Thêm vào đó, cần kiểm soát chặt chẽ điều kiện phản ứng PCR để tránh mỏi bắt cặp không đặc hiệu. Kỹ thuật PCR đặc hiệu alen chính là cơ sở để phát triển một số công nghệ xác định kiểu gen hiệu năng cao.
3.2 Công nghệ xác định kiểu gen hiệu năng trung bình
Loại công nghệ này phù hợp với các nghiên cứu hồi cứu. Các kỹ thuật thuộc loại này đòi hỏi thiết bị đặc biệt và người làm được đào tạo cao hơn. Không chỉ dùng cho nghiên cứu, các công nghệ này có thể được áp dụng trong xét nghiệm lâm sàng. Sự ra đời của các bộ kit thương mại hóa giúp giảm thời gian để thiết kế và tối ưu hóa quy trình xét nghiệm. Một số hệ thống phổ biến được miêu tả trong Bảng 4.1.
Trong các kỹ thuật xác định kiểu gen hiệu năng trung bình, kỹ thuật lại hóa ADN pha rắn (microarray) được áp dụng khá phổ biến, thường được coi là tiêu chuẩn vàng trong xác định kiểu gen cùng với kỹ thuật giải trình tự ADN. Kỹ thuật này cho phép xác định kiểu gen mang SNP phụ thuộc vào các điều kiện lai nghiêm ngặt (bắt cặp theo quy luật bổ sung). Phương pháp xét nghiệm này rất nhạy với sự khác biệt về cả độ dài và trình tự của cả các oligonucleotid gắn chi thị (probe) và các oligonucleotid dich. Một trong những ứng dụng này là tạo ra các GenChip thương mại có thể xác định kiểu gen đồng thời của nhiều alen, trong đó xét nghiệm kiểu gen được FDA phê chuẩn sớm nhất và hiện nay vẫn đang được sử dụng phổ biến trong lâm sàng là bộ kit AmplichipTM CYP450 (Hình 4.2). Bộ kit cho phép xác định kiểu gen của 27 alen của CYP2D6 và ba alen của gen CYP2C19 liên quan đến các kiểu binh chuyển hóa khác nhau. Xét nghiệm được giới thiệu để đánh giá tình trạng chuyển hóa của bệnh nhân đối với từng loại thuốc là cơ chất cho các isoenzym CYP450 2D6 và 2C19 và đối với việc điều chỉnh liều ở bệnh nhân, cho phép phân biệt các kiểu gen tương ứng với hai loại kiểu hình của CYP2C19, bốn loại kiểu hình của CYP2D6, để đạt được hiệu quả điều trị và tránh nguy cơ tác dụng không mong muốn nghiêm trọng. Một số hướng dẫn điều trị đã được ban hành để điều chỉnh liều tương ứng với kiểu gen CYP2D6 và CYP2C19 của bệnh nhân.

| Tên hệ thống | Tóm tắt nguyên lý kỹ thuật | Đặc điểm |
| Tagman (Applied Biosystems) | Real-time PCR | Hệ thống cho phép phân tích số lượng bản copy và mức độ biểu hiện mARN với 384 giếng đồng thời |
| Infiniti (Autogenomics) | Microarray | Có thể tiến hành phản ứng PCR đồng thời với 24 mẫu |
| Tag-it Mutation Detection (Luminex Molecular Diagnostics) | Multiplex PCR với các vi cầu chứa chất huỳnh quang đặc hiệu | Có thể xét nghiệm đồng thời 100 gen khác nhau trong một tube phản ứng, 24 mẫu cùng một lúc |
| Pyrosequencing (Qiagen) | Giải trình tự trong khi tổng hợp chuỗi, phát hiện bằng huỳnh quang | Ưu điểm so với các kỹ thuật khác là cho biết trình tự xung quanh vị trí có SNP, nhờ đó, giúp tăng độ tin cậy của xét nghiệm. Cho phép phân tích 24 hoặc 96 mẫu đồng thời. Cho phép phát hiện không chỉ SNP mà còn các loại đột biến khác |
| Invader Assay (Hologic) | Cắt bằng enzym giới hạn đặc hiệu cấu trúc | Cho phép phân tích đồng thời 32 mẫu |

3.3 Công nghệ xác định kiểu gen hiệu năng cao
Với lợi thế cả về chi phí và tốc độ, công nghệ này phù hợp với các nghiên cứu có cỡ mẫu lớn, số lượng đa hình lớn nhưng cũng đi kèm với những yêu cầu cao về thiết bị, chi phí và kỹ thuật viên. Các kỹ thuật thường được áp dụng bao gồm khối phổ và sắc ký lỏng hiệu năng cao biến tính.
Phương pháp khối phổ
Đây là phương pháp có thông lượng cao, là một kỹ thuật dùng để đo đạc tỷ lệ khối lượng trên điện tích của ion, phổ biến là công nghệ ion hóa giải hấp thụ laser MALDI - TOF, có thể xác định kiểu gen chính xác dựa trên việc phát hiện chính xác khối lượng phân tử của sản phẩm acid nucleic. Ngược lại với các phương pháp xác định kiểu gen trên dựa trên ánh sáng, huỳnh quang hoặc gel, phương pháp khối phổ phân biệt các phân tử ADN dựa trên một khối lượng xác định. Do phương pháp này sử dụng chủ yếu như một phương pháp phát hiện nên thường được kết hợp với các phương pháp xác định kiểu gen phân biệt alen, chẳng hạn như phương pháp lai đặc hiệu alen. Mặc dù phương pháp này có độ chính xác rất lớn và thông lượng cao (có khả năng xác định từ 10.000 - 50.000 kiểu gen mỗi ngày), nhược điểm chính của khối phổ là chi phí đầu tư cho thiết bị cao và các quy trình tinh chế sản phẩm nghiêm ngặt trước khi chạy qua khối quang phổ kế.
MassARRAY system là hệ thống thương mại phổ biến sử dụng phân tích khối phổ để phân biệt các alen. Hệ thống này có thể dùng cho các dự án lập bản đồ gen với những bộ kit thương mại đặc hiệu.
Phương pháp DHPLC - sắc ký lỏng hiệu năng cao biển tính (denaturing high- performance liquid chromatography)
Đây là phương pháp độc đáo vì có thể được sử dụng cho cà khám phá đa hình gen và xác định kiểu gen, DHPLC sử dụng cột pha đảo cặp ion để phân biệt giữa các alen biến thể và alen không biến đổi. Một sản phẩm PCR (200 - 700 bp) từ một mẫu có kiểu gen đã biết (mẫu tham chiếu) được so với các sản phẩm PCR của các kiểu gen chưa biết. Ưu điểm của DHPLC là có thông lượng cao, quy trình tự động cũng như khả năng sử dụng các mồi PCR qua biến đổi và các sản phẩm PCR chưa được tinh chế. DHPLC cũng có lợi thế là có thể phát hiện kiểu đa hình mới. Những hạn chế chính của DHPLC là các bước tối ưu hóa cần thiết để đạt được kết quả phân biệt cao. Ngoài ra, độ tin cậy của phương pháp phụ thuộc vào độ tái lập của thời gian lưu.
3.4 Công nghệ xác định kiểu gen hiệu năng siêu cao
Khi không xác định được gen ứng viên và biến thể mục tiêu rõ ràng, các vi mảng (chip ADN bead array) cho phép quét nhanh để giới hạn được các vùng gen mục tiêu cụ thể. Loại công nghệ này cho phép phân tích một số lượng lớn gen và SNP hoặc thậm chỉ toàn bộ hệ gen trong một xét nghiệm. Các dữ liệu thu được đòi hỏi phải có phân tích thống kê phức tạp, thường được áp dụng để khám phá những vùng gen mới chưa từng được biết có liên quan đến đáp ứng thuốc.
Hệ thống BeadArray System (Illumina)
Công nghệ này dựa trên nguyên lý của PCR đặc hiệu alen và phép lai trên từng chuỗi ADN, cho phép phân tích 96 - 1536 SNP đồng thời với một loại polymerase đặc biệt giúp phân tích 300.000 kiểu gen trong vài giờ và có thể xét nghiệm cùng lúc với 16 - 96 mẫu. Phiên bản mới nhất của hệ thống này (Infinium) cho phép phân tích đồng thời không giới hạn số gen.
Hệ thống Genome-Wide Human SNP Array 6.0 (Affymetrix)
Hệ thống này bao gồm 1,8 triệu marker di truyền, bao gồm 946.000 đầu dò phát hiện số lượng bản copy, cho phép xét nghiệm đồng thời 48 - 96 mẫu. Với quy mô đó, hệ thống này phù hợp với những nghiên cứu GWAS quy mô rất lớn. Bên cạnh đó, Affymetrix còn có những hệ thống xác định kiểu gen mục tiêu cho phép xét nghiệm đồng thời 3.000 – 20.000 SNP để dùng cho các nghiên cứu sâu hơn.
3.5 Các công nghệ giải trình tự song song quy mô lớn
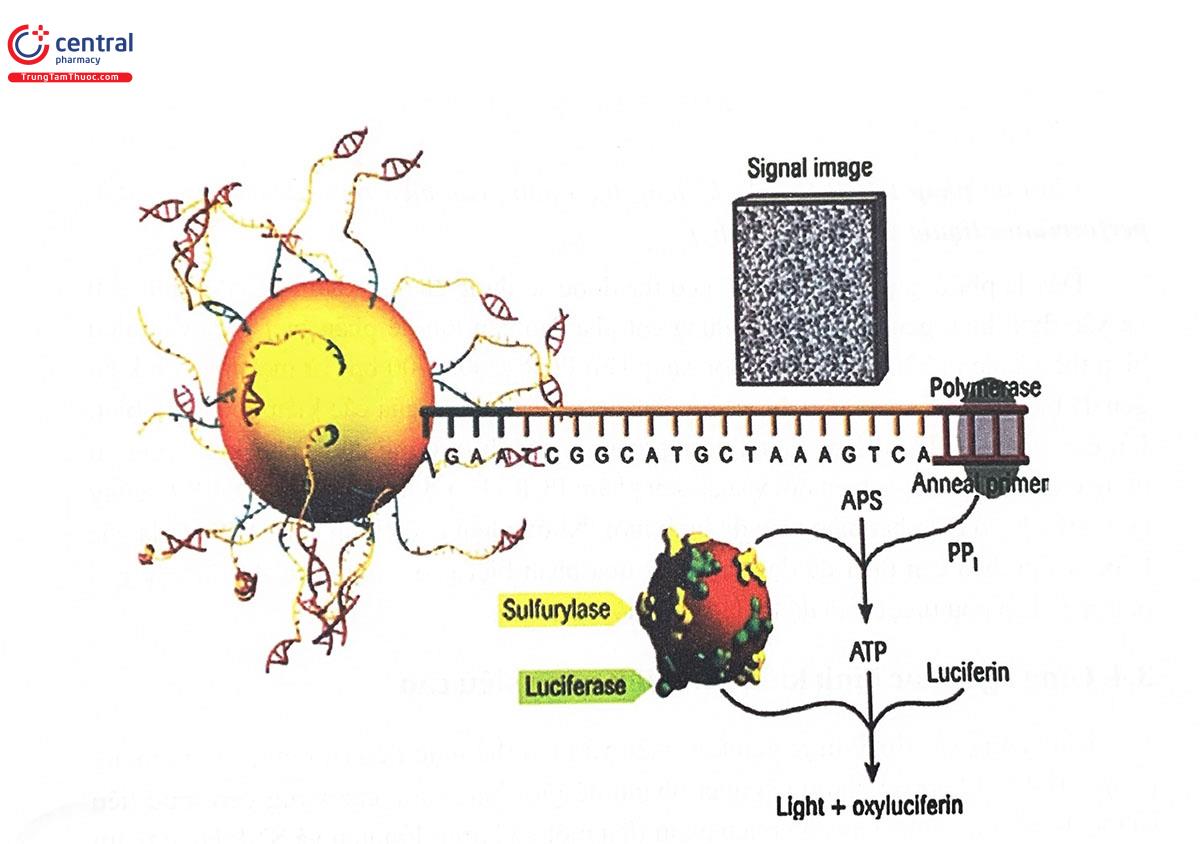
Mặc dù giải trình tự gen là tiêu chuẩn vùng trong việc xác định kiểu gen nhưng về hiệu quả kinh tế, chỉ phù hợp với những dự án nghiên cứu rất lớn. Sự phát triển của công nghệ giải trình tự gen song xong quy mô lớn (hay còn gọi là công nghệ giải trình tự thổ hệ mới - Next generation sequencing (NGS)) giúp giải quyết vấn đề này vì cho phép tổng hợp các trình tự ADN có kích thước lên tới 100 triệu base trong vòng 2 ngày. Các công nghệ này có thể được sử dụng để xác định các loại ăn hình của gen ứng viên hoặc sàng lọc tìm ra đa hình mới của một gen. Thêm vào đó, với công nghệ này, việc giải trình từ toàn bộ hệ gen không còn là vấn đề khó khăn lớn. Đây chính là yếu tố giúp nghiên cứu và ứng dụng Gen được học phát triển mạnh mẽ trong thời gian gần đây.
| Tên hệ thống | Tóm tắt nguyên lý kỹ thuật | Đặc điểm |
| 454 sequencing technology (Roche) | Pyrosequencing trên pha rắn (giải trình tự gen bằng cách tổng hợp hợp các mảnh nhỏ AND rồi sau đó gắn lại bằng phản ứng enzym | Độ chính xác, hiệu quả và hiệu suất cao hơn rất nhiều so với phương pháp Sanger. Ngoài ra, có thể dùng để phân tích transcriptome, xác định các vị trí gắn yếu tố phiên mã, phân tích methyl hóa. Hệ thống này đã được sử dụng để giải trình tự toàn bộ hệ gen người và xác định tỷ lệ tế bào ung thư mang đột biến mới của bệnh nhân. |
| SOLiD (Applied Biosystems) | Phát hiện và lại hóa oligonucleotid | Có thể phân tích 20 Gb trình tự ADN trong mỗi chu kỳ chạy (6 ngày). Hệ thống này có độ linh hoạt cao, có thể giải trình tự các vùng gen mục tiêu nhằm xác định SNP mới. Ngoài ra, có thể dùng để giải trình tự toàn bộ hệ gen, phân tích transcriptome, phân tích methyl hóa. |
| Genome Analyzer (Illumina) | Kết hợp giữa phân tích tế bào dòng chảy với lai hóa oligonucleotid | Cho phép phân tích 1,5 Gp trong mỗi chu kỷ 2,5 ngày, phân tích đồng thời tới 20 mẫu cho mỗi kênh. Hệ thống được áp dụng rộng rãi trong giải trình tự toàn hệ gen, giải trình tự vùng gen mục tiêu, phân tích transcriptome, phân tích methyl hóa. |
4 Xét nghiệm kiểu hình
Bản chất của xét nghiệm kiểu hình trong gen dược học là những xét nghiệm cho phép định lượng được ảnh hưởng của sự thay đổi về cấu trúc, số lượng, chức năng protein đối với số lượng/ đáp ứng của thuốc liên quan trong cơ thể. Trong Gen được học, xét nghiệm kiểu hình thường gặp nhất đối với việc nghiên cứu về đa hình enzym chuyển hóa thuốc, do đó, kiểu hình được quan tâm chính là hoạt tính của enzym. Điều quan trọng nhất trong xét nghiệm kiểu hình là lựa chọn được các chất chỉ thị (probe). Chất chỉ thị thường là một cơ chất đặc hiệu của enzym chuyển hóa, có độ an toàn cao, có thể dễ dàng định lượng trong máu, nước tiểu... Để đánh giá hoạt tính của một enzym chuyển hóa thuốc, người ta thường định lượng và tính tỉ số giữa nồng độ của chất có thị với nồng độ sản phẩm chuyển hóa chính của nó, dưới tác dụng của enzyme mục tiêu, thường lấy mẫu trong mẫu hoặc nước tiểu.
Nồng độ trong huyết tương và nước tiểu của các chất chỉ thị và sản phẩm chuyển hàn chính của chúng thường được định tương bằng HPLC pha đảo hoặc sắc ký lỏng khối phố. Ngoài ra, có thể định kinh, định lượng protein bằng phương pháp xác định bằng hình ảnh kết hợp triển dịch như phương pháp hóa mô miễn dịch.
5 Ứng dụng công nghệ dữ liệu lớn trong nghiên cứu Gen dược học
Sự phát triển của công nghệ, đặc biệt là công nghệ giải trình tự gen thế hệ mới đi kèm theo những nghiên cứu GWAS quy mô lớn và nghiên cứu giải trình tự toàn bộ hệ gen làm cho khối lượng dữ liệu ngày càng gia tăng, số lượng biến số tăng từ vài trăm biến số đến hàng triệu biến số độc lập. Do đó, ứng dụng của tin sinh học và đặc biệt là công nghệ dữ liệu lớn ngày càng phổ biến trong nghiên cứu gen được, bao gồm từ thu thập dữ liệu đến xử lý, phân tích dữ liệu, đọc kết quả, áp dụng vào trong thực hành lâm sàng. Ví dụ: Một nghiên cứu trên toàn bộ hệ gen với 1000 mẫu như các dự án 1000 genome đang phổ biến ở nhiều nước hiện nay sẽ cho ra khoảng 300 tetrabyte dữ liệu lưu trữ. Đối với mỗi mẫu, cần khoảng 45 giờ để xử lý dữ liệu với những máy tính hiện đại. Công nghệ điện toán đám mây và các máy tính hiệu năng cao giúp tăng tốc độ xử lý các dữ liệu đó. Các công nghệ dữ liệu lớn cho phép nghiên cứu mối liên quan của hàng triệu biến số di truyền thu được với đáp ứng điều trị trong lâm sàng. Các hướng tiếp cận mới như genomics hệ thống, kết hợp các cơ sở dữ liệu omics đa dạng trở thành những chiến lược hiệu quả để làm sáng tỏ mối liên quan giữa kiểu gen và đáp ứng điều trị.
Các cơ sở dữ liệu tìm kiếm về hệ gen (Genome browser), là một khái niệm mới, bao gồm các công cụ và cơ sở dữ liệu với giao diện hình ảnh giúp người dùng tra cứu, lưu giữ, phân tích và chủ giải các dữ liệu genomics.
| Tên cơ sở dữ liệu | Cơ quan quản lý | Ứng dụng chính trong nghiên cứu gen dược |
| NCBI | Trung tâm Thông tin Công nghệ sinh học Quốc gia - Viện Sức khỏe Hoa Kỳ | Cung cấp các tài nguyên dữ liệu sinh học bao gồm Genbank, thư viện các tạp chí chuyên ngành, công cụ tìm kiếm BLAST... Cho phép tìm kiếm các thông tin về SNP, trình tự ADN, ARN, protein, cho phép phân tích được mối liên quan giữa kiểu gen với kiểu hình đáp ứng lâm sàng thông qua công cụ ClinVar. Ưu điểm lớn nhất là cho phép thể hiện được thông tin về trình tự gen dưới dạng bản đồ di truyền qua công cụ Mapviewer. Các dữ liệu đều được cung cấp miễn phí. |
| Gene card | Trung tâm Hệ gen người Crown, Viện Khoa học Weizmann, Israel | Cung cấp tài nguyên dữ liệu về hệ gen người, bao gồm cȧ genomic, proteomic, transcriptomic, di truyền, các thông tin về chức năng và vai trò trong lâm sàng của các gen đã được biết. Cho phép tổng quan nhanh chóng các thông tin về y sinh học liên quan đến một gen cụ thể nào đó và cả các nhà cung cấp những sinh phẩm và thiết bị cần thiết cho việc nghiên cứu một gen nào đó. |
| Ensembl | Viện Tin sinh học châu Âu và Viện Wellcome Trust Sanger | Cung cấp các công cụ cho phép dự đoán và phân loại về chức năng của 1 protein, dự đoán các đột biến làm giảm hoặc mất chức năng protein. Ngoài ra, cho phép người dùng thể hiện cấu trúc exon-intron của một gen. |
| 1000 genomes | Gồm nhiều nhóm nghiên cứu đa quốc gia | Xuất phát từ dự án 1000 genomes, cho phép người dùng tiếp cận với các thông tin về biến thể gen, tần suất của các alen trong từng quần thể, kể cả tần suất của những alen hiếm, thông tin về các haplotype. Dữ liệu được cung cấp miễn phí. |
| Dự án KRG | Trung tâm Khoa học Genome, Viện sức khỏe Quốc gia Hàn Quốc | Cung cấp thông tin về các biến thể trong toàn bộ gen của người Hàn Quốc, các thông tin về đa hình, đột biến, về sự đa dạng của hệ gen, sự khác biệt về tần suất alen giữa người Hàn Quốc và các chủng tộc khác, các chú giải về chức năng của gen. Dữ liệu được cung cấp miễn phí. |
6 Tài liệu tham khảo
1. Phùng Thanh Hương, Đỗ Hồng Quảng, Nguyễn Văn Rư, Nguyễn Thị Lập, Nguyễn Quốc Bình. Gen dược học - Ảnh hưởng của gen đến đáp ứng thuốc. Trường Đại học Dược Hà Nội, Bộ môn Hóa Sinh - Khoa Công Nghệ Sinh Học. Tải PDF sách TẠI ĐÂY
2. ECM Tonk, D Gurwitz, A-H Mait ADN-van der Zee, ACJW Janssens (2017), Assessment of pharmacogenetic tests: presenting measures of clinical validity ADN potential population impact in association studies, Pharmacogenomics Journal (2017) 17, 386-392.
3. ECM Tonkl, D Gurwitz2, A-H Maitland-van der Zee3 and ACJW Janssens (2017), Assessment of pharmacogenetic tests: presenting measures of clinical validity and potential population impact in association studies, Pharmacogenomics Journal (2017) 17, 386-392.
4. Eun-Young Cha, Hye-Eun Jeong, Woo-Young Kim, Ho Jung Shin, Ho-Sook Kim and Jae-Gook Shin (2016), Brief introduction to current pharmacogenomics research tools, Transl Clin Pharmacol Vol. 24, No.1, Mar 15, 2016.
5. M. J. Deenen (2011), Clinical Pharmacology: Pharmacogenetics: Opportunities for Patient-Tailored Anticancer Therapy, The Oncologist 2011;16:811-819.
6 . Ruowang Li, Dokyoon Kim & Marylyn D Ritchie (2017), Methods to analyze big data in pharmacogenomics research, Pharmacogenomics 2017 Jun;18(8):807-820.
7. Russ B. Altman (2012), Principles of Pharmacogenetics and Pharmacogenomics, Cambridge University Press.
8. Srinivasan BS et all. (2009). Methods for analysis in pharmacogenomics: lessons from the Pharmacogenetics Research Network Analysis Group. Pharmacogenomics. 10(2):243-51.
9. Wu AH, (2013). Genotype and phenotype concordance for pharmacogenetic tests through proficiency survey testing. Arch Pathol Lab Med. 137(9): 1232-6.
10. Despina Sanoudou (2012). Clinical Applications of Pharmacogenetics. Intechopen.
